
Glossary
April 2020
VELVET SOUND – Audio terminology
The terminology used to describe audio products is very specific. There’s a lot to learn, and AKM’s audio engineers can help by walking through some of the basics.
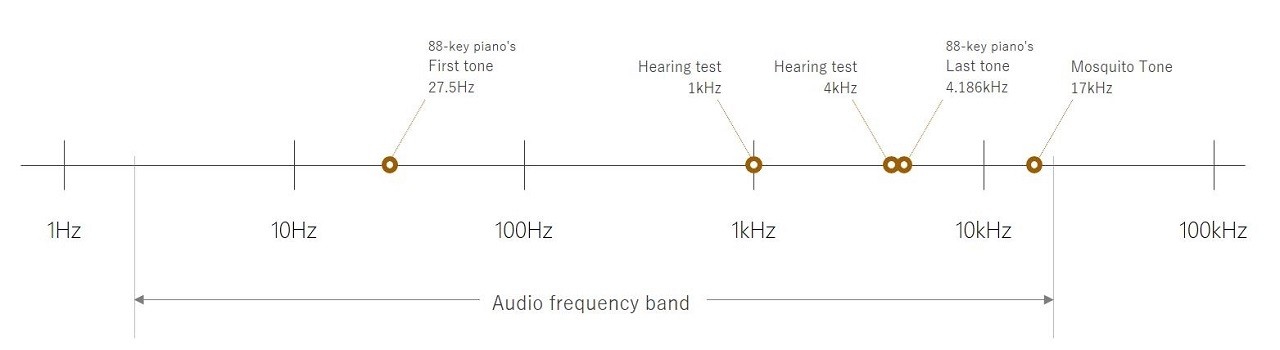
The audible frequency band (the part of the spectrum that humans can hear) is about 20Hz to 20kHz (although we lose some of the higher end of that range as we get older). For this reason, audio characteristics are typically measured (and described) within this range.
Even though we can’t generally hear sounds above 20kHz, we often take noise measurements up through much higher frequencies (this is referred to as out-of-band noise).
In practical terms, resolution is a description of the accuracy of a sample of digital audio data and is specified in bits. As an analogy, think of the loudness of a particular audio sample as its length, as measured on a 30cm ruler. If the maximum loudness of a sample is the full 30cm length of the ruler, then subdividing that ruler into 1mm notches yields a resolution similar to what is possible with 8-bit data (2 to the power of 8 = 256).
Let's go further – audio CDs contain 16-bit data (2 to the power of 16 = 65,536). To achieve that accuracy on the 30cm ruler, each notch would be about 4.5um wide – this is about 1/10 the thickness of a human hair; resolution has increased, and the ruler can make more accurate measurements.
DVDs contain 24-bit audio data. Eight more bits may not sound like a lot, but they allow for much higher resolution: to match that, the 30cm ruler would have to be broken up into 18nm increments (about the width of a bacterium). Moving further still to 32-bit audio data would allow for about 4.3 billion increments on the ruler, each about the width of a helium atom (about 70pm).
Just as increasing a digital camera’s resolution allows for a clearer, more lifelike image, higher resolution in sound reproduction gets the listener ever closer to hearing the recorded sound as it originally occurred. Conversely, lowering resolution by using a smaller bit depth leads to quantization error, which is perceptible as noise.
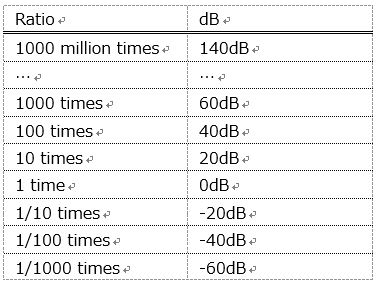
dB is a unit that expresses the ratio of loudness and signal strength. d (decimal) is a prefix with the meaning of 1/10. Human senses such as loudness are proportional to the logarithm of actual physical quantities. For this reason, the sound is also expressed in dB, which is the quantity to make it easier for humans to recognize.
Roughly speaking, in the audio industry, “(digits-1) x 20” is dB.
The signal to noise ratio (S/N, or SNR) is the ratio of maximum signal output to the noise level when no input signal is applied to the audio system. S/N is measured in decibels (dB), and a 1kHz sine wave is typically used as the audio stimulus when taking this measurement.
Dynamic range is the ratio of maximum signal output to the noise level present when a -60dBFS signal (this is very quiet) is applied, and it is also measured in dB. The DR specification is very similar to the SNR spec but is a more practical measurement, since any system will produce some level of noise when a signal is run through it. Recall that reduced bit depth leads to increased quantization error, which we hear as noise; this will directly affect an audio system’s dynamic range. Another thing to keep in mind is that the amount of noise in the system limits the quietest signal that can be reproduced; fundamentally, you can’t hear a recorded sound if it’s quieter than the system’s noise.
When a system’s DR and/or SNR are low (bigger DR = better), you’ll hear a hissing sound, especially during quiet musical passages, or while the system is paused (although some systems will automatically mute in the latter case). It’s very easy to hear this noise if the volume is turned up very high, but be careful if trying this out at home – when the music kicks in again, you may blow your ears out!
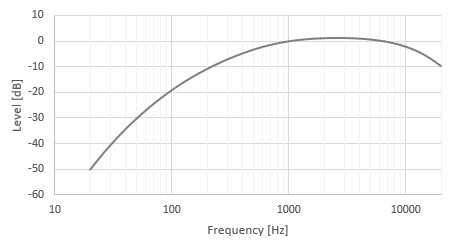
The frequency response of the human ear is non-linear with respect to frequency and perceived loudness; as shown in this graph, our hearing has a peak around 2 to 3kHz, but we hear sounds below 100Hz quite softly. This A-weighting curve can be used to compensate for that non-linearity when measuring noise, as we typically want to know how that noise will actually sound to a human listener. S/N and DR are therefore usually calculated with an A-weighted curve.
Total Harmonic Distortion + Noise (THD+N) and Signal to Noise + Distortion (S/N+D) are two ways to describe the same aspect of an audio system. In both cases, we are looking for the relationship of the system’s total output to its residual harmonic noise. Harmonic noise is measured by introducing a stimulus signal to the system and capturing the total output, which will include harmonic distortion and noise. We then subtract the stimulus signal from the total output, and the residual harmonic noise is what remains.
THD+N = (Distortion + Noise)/Signal.
This is the ratio of the system’s residual harmonic noise to the system’s total output. The noise power will be a smaller quantity, so this specification will be negative if expressed in dB.
S/(N+D) = Signal/(Distortion + Noise).
This is the ratio of the system’s total output to the residual harmonic noise and will be positive if expressed in dB.
In both cases, the larger the absolute value, the smaller the effect of the noise and distortion components; the harmonic distortion is typically difficult to hear in the presence of a strong signal. Excessive THD makes music sound harsh and irritating, but too little harmonic distortion can sound unnatural and dull; in the latter case, THD may actually be added in order to make the system sound warmer, or more analog-like.
You may recall that A-weighting is used when calculating DR and SNR, because in those cases, we are concerned with how noise is perceived by human ears. A-weighting is not applied in a THD+N calculation, as it is an objective measurement of how accurately the original signal is reproduced by the system, independent of the human ear’s non-linear frequency response.
This specification is commonly referred to as crosstalk and refers to leakage from channel to channel. For example, in an ideal system, the signal corresponding to the left channel should not be present in the right channel at all, and vice versa. In a real-world system, crosstalk can occur for various reasons, but experimental results show that if crosstalk is limited to 30dB, listeners will have no issue distinguishing the two channels clearly. A typical audio IC has crosstalk performance of 90dB or better, so this is normally not a problem.
This specification describes the differences in output level from channel to channel; ideally, if all channels are configured with the same amount of gain, and the same signal is applied to all of them, then the output level from all channels should likewise be the same. For most modern audio products, this mismatch is very low. This is important, because gain mismatch can be very distracting and disrupts stereo imaging. Many audio systems allow the user to adjust the balance from left to right (or on a channel-to-channel basis in a larger multichannel system), but this is usually to compensate for speaker placement, rather than to deal with gain mismatch.
* Please refer to the JEITA Standard CP-2402A for more information.

